
Graphing Effects with ggplot2 and effects
A step-by-step walkthrough on graphing with extensive illustrations, examples, and code snips.

The Dataset
The data I’ll be using to illustrate these points comes from an open-source dataset available from the carData package in R. The KosteckiDillon dataset contains migraine headache logs from over 100 patients who were enrolled in a bio-feedback treatment program. The patients provided information about:
sex
age
airq, a measure of air quality
medication, the amount of medication that patients received
hatype, the type of migraine headache they experienced
What Makes for a Good Graph?
“Clutter and confusion are not attributes of data – they are shortcomings of design.”
My favorite advice about graphs comes from Edward Tufte, who has spent much of his life collecting graphs and cataloging what makes them work (or not). Tufte encouraged statisticians to apply the principles of Cognitive Load Theory (Sweller, 1988) to their visualizations by reducing chart-junk, nonessential information depicted on a graph, and maximizing the data-to-ink ratio. According to Tufte - and the educational psychology literature more broadly - the best graphs contain only the essential information and nothing more. These two principles inform most of my decisions for visualizing data.
If you’d like to learn more, you can read some of Tufte’s amazing work yourself. For example, you may enjoy this interesting study in minimalism in which Tufte gradually erases the lines of a boxplot. And if you work or study at The University of Alabama in Huntsville, you can find all of Edward Tufte’s books on the graphical display of information on the third floor of The Salmon Library (QA276.3.T83; you’re welcome).
Creating a Model
The data collected by Kostecki-Dillon allows us to answer two important research questions about migraine medication:
RQ1: Does migraine medication help reduce the prevalence of migraine headaches?
RQ2: If so, what dose is required for maximal efficacy?
Since our outcome measure is binomial (people either experienced a headache or did not), we’ll run a logistic regression. Additionally, this is repeated-measures data, so this regression will be a mixed-effects/multi-level model:
A mixed effects logistic regression answered two research questions about migraine treatment: Is migraine treatment effective and, if so, what does is required to reduce headache frequency. This full-factorial model contained time (0 - 99 days) and medication (none, reduced dose, continued dose) as predictors in the fixed effect structure. The random effect structure allowed the intercept and time slope to vary across participants, controlling for individual differences in headache prevalence and medication efficacy, respectively. Time and medication were means-centered and effect-coded prior to analysis to reduce structural multicollinearity in the model; time was also log-transformed and scaled to account for the non-linear relationship in medication efficacy (i.e., eventually, futher improvement is not evidenced) and to improve model convergence.
Graphing the Effects
Although there are many graphics packages out there, I prefer to use the ggplot2 and effects libraries for their flexibility: ggplot2 provides great control over how data is displayed and effects can be used with many different analyses. Readers interested in learning more about why I prefer to use this approach over others can skip to the bottom of the post for a full discussion.
Creating the Graphing Dataframes
When a statistician reports an analysis, the graphical illustrations must reflect the analysis rather than the observations contained within the dataset. An analysis models the relationships between predictors and an outcome, including some amount of error so that the model can be generalized out-of-sample (i.e., to other groups of people). Consequently, a graph must reflect all aspects of the model, including the predicted values (rather than the observed ones) and the appropriate error region.
The Effect( ) function in the effects library accomplishes this by calculating predicted values from the regression equation for specific variables. The function includes many parameters (for a full list, see Fox’s page here), but I generally use three:

For example, if I wanted to graph the main effect of time, my code would look like this:

This code will use the regression equation produced in model2 to obtain predicted values (fit) for the time.t variable at 0, 25, 50, 75, and 99 days into treatment:

Similarly, if I wanted to graph the main effects and interaction between time and medication, my code would look like this:

This code will use the regression equation produced in model2 to obtain predicted values (fit) for the time.t variable at 0, 25, 50, 75, and 99 days into treatment for patients who received no medication (none), who continued their prescribed dose, or who reduced their prescribed dose:
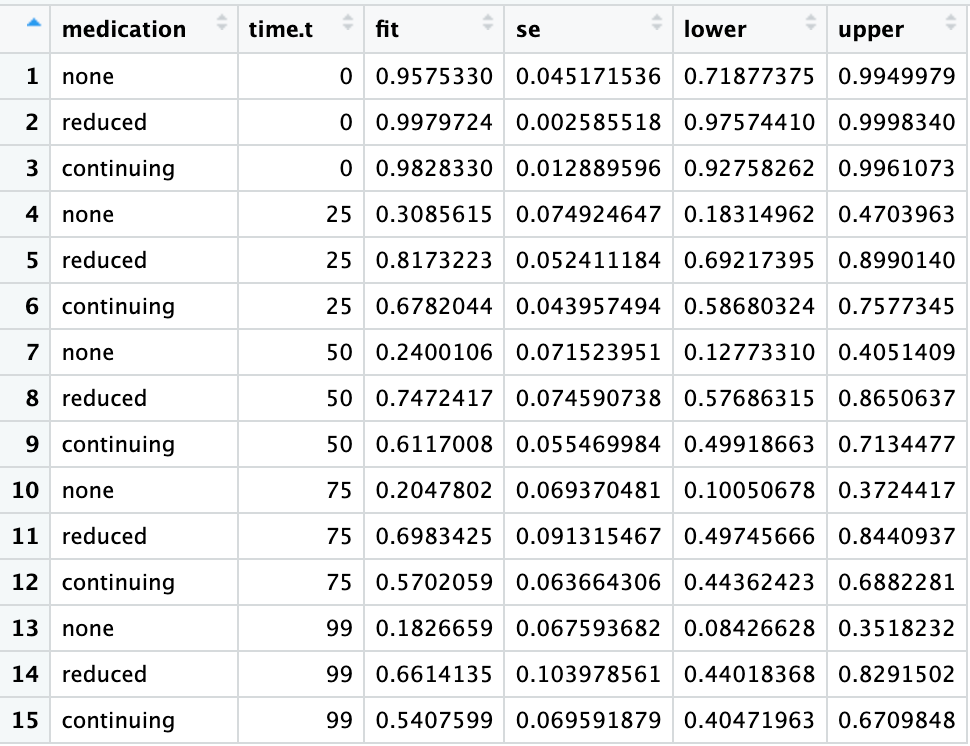
Creating the Graphing Canvas
The next step is to decide how you want variables oriented on your graph. The ggplot( ) function in the ggplot2 library determines how your graph will look. There are many ways to customize a graph (for more information, including a cheat sheet, see Wickham’s page here). Here are the features I use most frequently:

For example, if I wanted to graph the main effect of time with the lower and upper 95% confidence intervals from the effects package as the boundaries of my error ribbon, my code (and subsequent graphing canvas) would look like this:
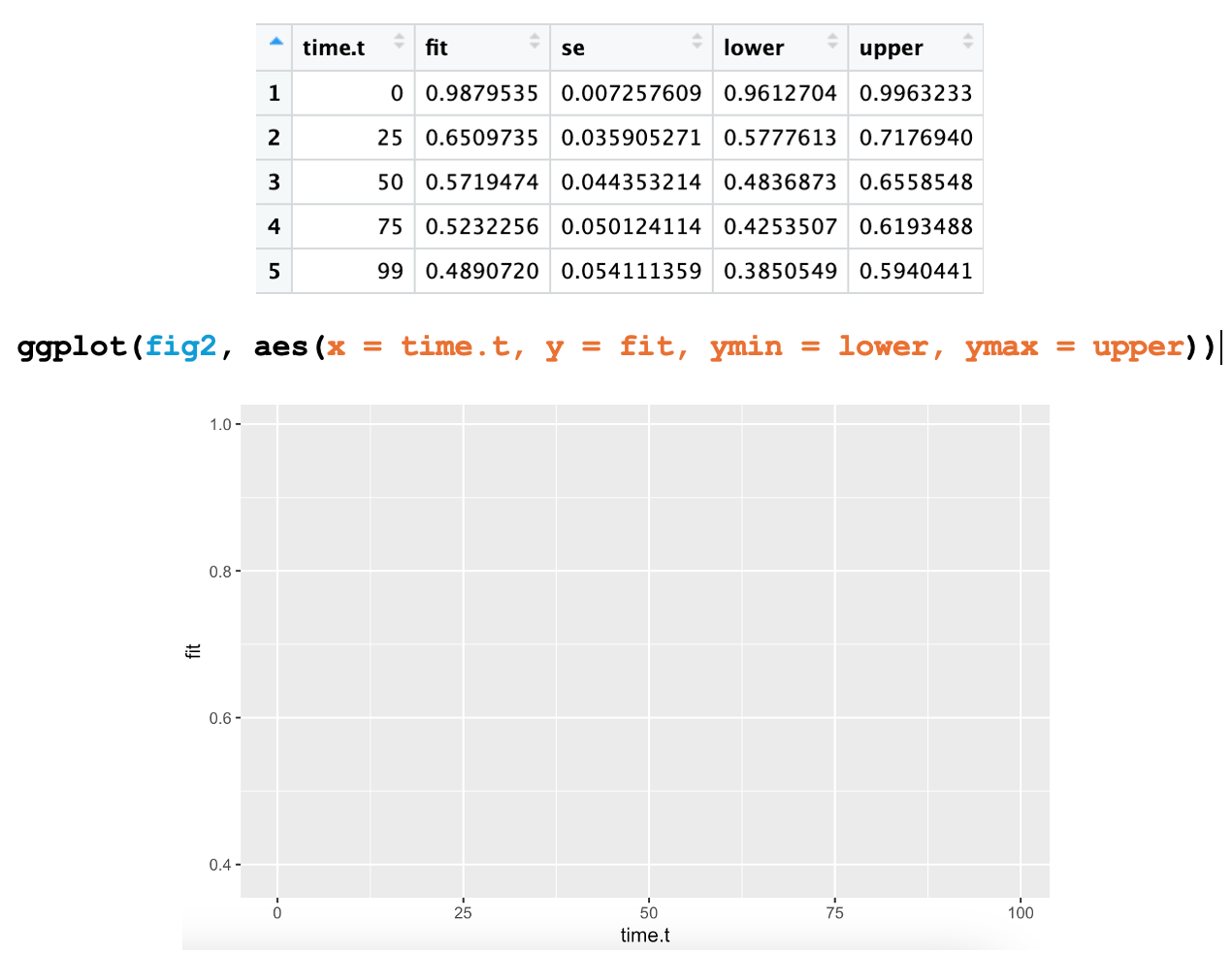
Here’s another example that graphs the main effects of time, medication, and their interaction with the lower and upper 95% confidence intervals:

I didn’t recreate the graph here because grouping variables are only displayed through elements, such as geom_line( ) and geom_ribbon( ):

We can use these commands to spruce up our interaction graph by adding them to the existing lines of code:
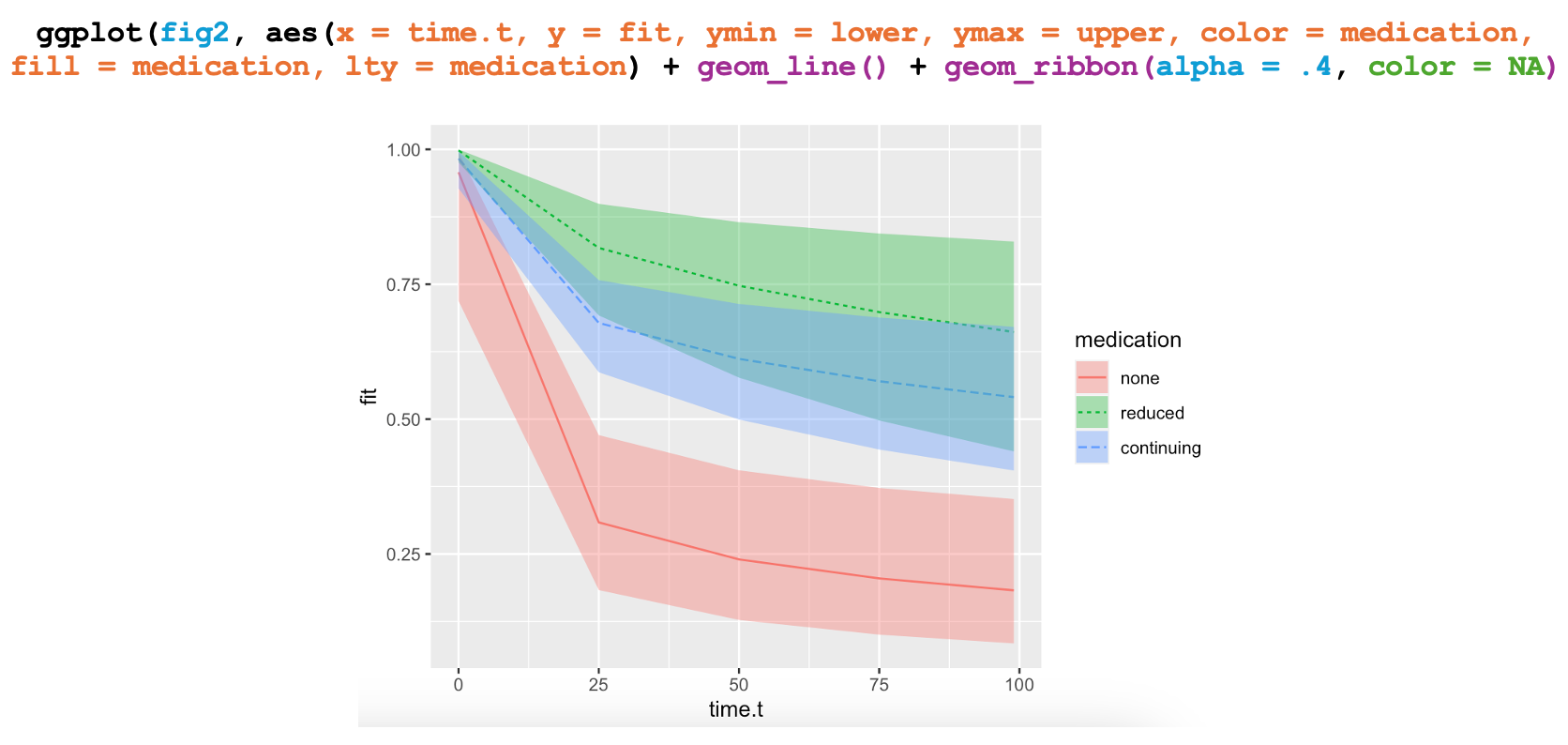
Getting Rid of Chart Junk
I work in the discipline of psychology where we adhere to APA 7th edition guidelines for figures (you can read more about that here). To bring my graphs into compliance, I always include the following lines of additional code:

Here’s how those lines improve our existing graph1:

Why Not Use [Insert Function/Package Here] for Graphing?
I often see students use a variety of other functions and packages to create graphs of their outcome variables. Here are some reasons I avoid these:
The sjstats package does not provide control over the aesthetics, making it difficult to produce publication-ready graphics.
The coefplot( ) and stat_smooth(method = “lm”) functions assume normally distributed residuals. These functions can be used to plot linear regressions, but cannot be used to illustrate the predicted values from mixed effects or generalized linear models (note the heteroskedastic error ribbons in our finished figure above)
The abline( ) function will plot a regression line but will not graph error ribbons. Additionally, this function assumes normally distributed residuals.
The geom_smooth( ) function plots a spline fit, a hyper-flexible function that overfits data relative to the analysis you likely ran.
Closing Thoughts
Clear data visualization is an essential part of communicating results. While it is tempting to reduce visualization to a set of formulaic guidelines (e.g., “Always illustrate an interaction with a line graph.”), it is far more important to empathize with and consider audience needs. This tutorial doesn’t cover all of the features for graph personalization, but it gives you a place to start. I hope this post inspires you to visualize your results in new and intuitive ways.
Happy graphing!
Dr. V
If you are like me, you’ll notice that the patients who stopped taking medication (none) were less likely to have migraines than those who reduced or continued to take their prescribed dose. Although Kostecki-Dillon and her colleagues used a similar approach to analyze their data in 1999, their publication does not report this interaction. There are many possible explanations for this discrepancy, including this open-source data representing only a subset of the full dataset.